




Introduction
Reflection Llama-3.1 70B is revolutionizing AI models with its innovative reasoning and error-correction techniques. In just the last month, the model has been downloaded 20,689 times from Hugging Face. It employs a unique "Reflection-Tuning" approach, allowing the model to self-correct errors as it processes complex queries. This capability makes it stand out in a rapidly growing market for powerful AI models. By outputting internal thought processes within specific tags, Reflection Llama provides users with deeper insights into how it derives answers.
What is Reflection Llama
Reflection Llama-3.1 70B is an open-source large language model (LLM) trained using "Reflection-Tuning."
This advanced technique enables the model to critically assess its own reasoning, allowing it to correct mistakes in real time.
Reflection Llama can distinguish between its thought process, flagged by the <thinking> tag, and the final answer presented in the <output> tag.
This transparency is a leap forward in AI's ability to reason through complex problems.
Benchmarks and Performance
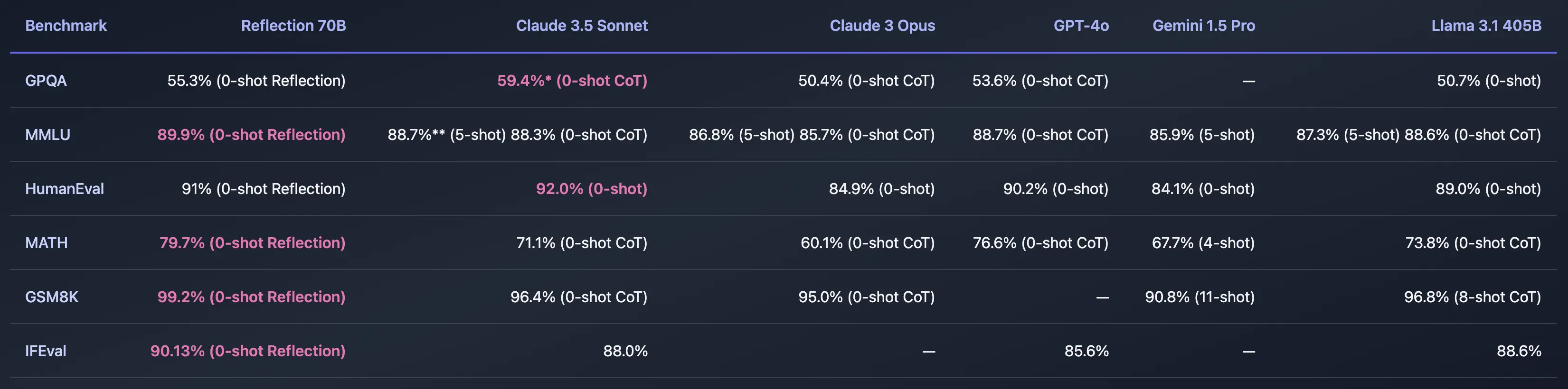
Reflection Llama-3.1 70B has undergone extensive benchmarking to ensure its reliability and effectiveness.
Tests were rigorously decontaminated using LMSys's LLM Decontaminator to avoid dataset contamination.
Only the final responses within the <output> tags were evaluated, providing a clear picture of its capabilities.
The model excels in reasoning-based tasks, significantly outperforming its peers in both open-source and proprietary models.
System Prompt and Chat Format
The system prompt driving Reflection Llama-3.1 70B is specifically designed to promote reflective reasoning.
It instructs the model to think through queries using <thinking> tags and issue final answers within <output> tags.
If errors are detected, they are corrected within <reflection> tags.
This structured format ensures greater accuracy and transparency.
Architecture and Special Tokens
Reflection Llama-3.1 70B shares its architecture with the Llama 3.1 70B Instruct model, but introduces special tokens like <thinking>, <reflection>, and <output>.
These tokens allow the model to separate reasoning from the final answers, making it more effective at problem-solving and error correction.
Dataset and Training Report
The model was trained primarily on synthetic data generated by Glaive AI. Synthetic data helps Reflection Llama-3.1 70B cover a broad spectrum of scenarios, enabling it to excel in areas where other models might struggle. A detailed training report will be released, offering insights into the dataset and methodologies used in developing this groundbreaking model.
Model Performance Tips
- Set the temperature to 0.7 for a balanced output between creativity and precision.
- Use a top_p value of 0.95 for better task performance.
- For complex tasks, provide instructions like “Think carefully” to prompt more thoughtful responses.
Conclusion
Reflection Llama-3.1 70B is a game-changer in the world of AI, offering advanced self-correction capabilities that enhance both reliability and transparency. Its unique architecture, robust benchmarks, and flexible system prompts make it a powerful tool for a wide range of applications. As the AI landscape continues to evolve, Reflection Llama is poised to remain at the forefront of innovation.
FAQ
- Q: What is Reflection Llama-3.1 70B? A: Reflection Llama-3.1 70B is a large language model (LLM) using "Reflection-Tuning" to self-correct its reasoning process, improving the accuracy and reliability of its outputs.
- Q: What is Reflection-Tuning? A: Reflection-Tuning is a process that allows the model to reflect on its reasoning, identifying and correcting errors before providing the final response.
-
Q: How does Reflection Llama-3.1 70B format its responses?
A: The model uses special tags:
<thinking>for reasoning,<reflection>for corrections, and<output>for final answers. - Q: How does Reflection Llama-3.1 70B perform on benchmarks? A: It outperforms many open-source and proprietary models in complex tasks requiring step-by-step reasoning, thanks to its reflective capability.
- Q: What datasets were used to train Reflection Llama-3.1 70B? A: The model was trained on synthetic data generated by Glaive AI, providing a diverse range of scenarios for self-reflection and reasoning.
-
Q: What are the special tokens used by the model?
A: Reflection Llama-3.1 70B uses
<thinking>,<reflection>, and<output>tokens to enhance transparency in its reasoning. - Q: What is the recommended temperature setting for best performance? A: For balanced performance, the recommended temperature setting is 0.7, and the top_p value is 0.95.
- Q: How can I use Reflection Llama-3.1 70B in my applications? A: The model uses the standard Llama 3.1 chat format, making it easy to integrate into systems that already support Llama models.
References
- Mattshumer. (2024). Reflection Llama-3.1 70B. Hugging Face.
- Unsloth. (2024). Reflection Llama-3.1 70B. Hugging Face.
- Ollama. (2024). Reflection Llama-3.1 70B. Ollama.





